New! Announcing support for images
We are adding image support to Zamba Cloud. You can now analyze both camera trap videos and images. We are still in the process of writing documentation for this feature, but you can use it in the same way as the video features explained below.
You can find more information on the 178 taxonomic classes that the official base model can identify
in the documentation
for the zamba Python package.
Zamba Cloud makes it easier to handle large amounts of camera trap data for research and conservation.
Zamba Cloud uses machine learning to automatically detect and classify animals in camera trap videos or images. You can use Zamba Cloud to:
All without writing a line of code!
To generate predictions for unlabeled videos/images
Zamba includes multiple state-of-the-art, pretrained machine learning models for different contexts. Each is publicly available and can be used to classify new videos/images.
To generate new predictions, you'll upload media files and receive a spreadsheet telling you what species are most likely present in each, allowing you to weed out false triggers and get straight to the files of interest.
After creating an account, you can either upload media files directly or point Zamba Cloud to an FTP server where your files are stored. Then, get back to your day while Zamba Cloud processes your media. You'll get an email when it's done. Simply log back into your account and a spreadsheet with labels for each media file will be waiting for you!
To train a model based on labeled videos/images
Users can upload additional labeled videos/images, and Zamba will train a new custom model.
After creating an account, you'll upload a set of videos/images and their correct species labels. These will be used to improve the base classification model (African species model for videos, the Global species model for images), building on what the model has already learned from thousands of training examples. The model can even learn to predict entirely new species and new ecologies, no matter where they are! Then you can go do some birdwatching, and you'll receive an email when your new model is ready. Your specialized model will then be available to classify any new media you upload to Zamba Cloud!
Step by step instructionsZamba Cloud comes with a few official model options that are pretrained for different contexts. The table below summarizes their relative strengths.
| Model | Geography | Relative strengths |
|---|---|---|
| Blank vs. non-blank | Central Africa, East Africa, West Africa, and Western Europe | Just blank detection, without species classification |
| African species | Central, East, and West Africa | Recommended species classification model for jungle ecologies |
| African species (slowfast) | Central, East, and West Africa | Potentially better than the default African species model at small species detection |
| European species | Western Europe | Trained on non-jungle ecologies |
| Global species (images) | Global | Trained specifically for images |
All models except the African species (slowfast) model use an image-based architecture. The slowfast model uses a video-native architecture, which in some cases can better capture motion to detect small species. Check out the zamba python docs for more model details.
To assess accuracy, model predictions were compared with labels manually applied by researchers and citizen scientists. Performance was measured on data that were not part of the model's training set, which provides a more accurate picture of how the model will perform on other new data (like yours!).
| Model | Top-1 accuracy | Top-3 accuracy |
|---|---|---|
| African species | 82% | 94% |
| African species (slowfast) | 61% | 80% |
| European species | 79% | 89% |
It's harder to report metrics for our large, global model that will be meaningful for all use cases. For most relatively common taxa, F1 scores (combination of precision and recall) are between 0.85 and 0.99, indicating reliable performance for many applications. For your use case, you can threshold the per-species probabilities to capture more images (and more false positives for a species) or fewer images (fewer false positives, but some true positives may be missing).
We've observed some general limitations to this model. Generally, small species (rodents and reptiles) perform worse, and there are some known issues with commonly confused marsupials, some bird species, and different kinds of antelopes.
If you want to see better accuracy for your use specific case, we created this model to be a base for custom, user-created models for specific habitats and geographies, so train away!
All the species models contain a blank output label in addition to the species labels, but blank detection works slightly different between the image and video models. In the image model, blank means that no animal was detected by MegaDetector, which has its own accuracy docs. For videos, there is an additional "blank vs. non-blank" detection model. This means that for videos either a species model or the blank model can be used for blank detection. The key difference is that the blank model only outputs the probability that the video does not contain an animal and does not do any species classification for non-blank videos. The table below compares blank performance between the African species model and the blank model.
| Model | Precision for blank videos | Recall for blank videos |
|---|---|---|
| Blank vs. non-blank | 83% | 89% |
| African species | 84% | 87% |
Our goal is to continually improve these algorithms, and you can help! The most valuable contribution to this effort is additional labeled data. Find out more about how you can submit a correction for the videos/images that Zamba Cloud got wrong. Or, if you have videos/images that are already labeled, you can share labeled data directly with us.
The blank vs. non-blank model only outputs the probability that the video is blank, meaning that it does not contain an animal. It does not provide any species classification.
The global image model predicts on 178 classes at varying taxonomic levels. While this model is a good first start for off-the-shelf, we created this model to be a base that is used for custom, user-created models for specific habitats and geographies.
Don't see what you're looking for? We are always open to expanding the list of species that Zamba can identify—consider training your own model with your own data to add species.
To begin, either sign up to create an account or log in to your existing account.
Sign Up Log InThis section walks through how to use Zamba Cloud if you don't know what species your footage contains and want to generate labels.
After logging in, you'll be taken to the Uploads page, where you will upload the media files you want Zamba Cloud to process.
There are two ways of submitting media files: Direct upload or FTP upload. Currently, the FTP upload option only supports videos.
Zamba supports dozens of image and video formats, so yours is likely covered. The specific list of video file formats is here, and for images, Zamba supports the file formats listed here.
Wondering how long it will take? See this FAQ question for more information.
Use this option to upload videos/images from local files on your computer.
This option currently only works for videos. In order to use FTP upload, your videos have to already be uploaded to an FTP server. Many large organizations and universities run FTP servers, which can be used to host data for Zamba Cloud.
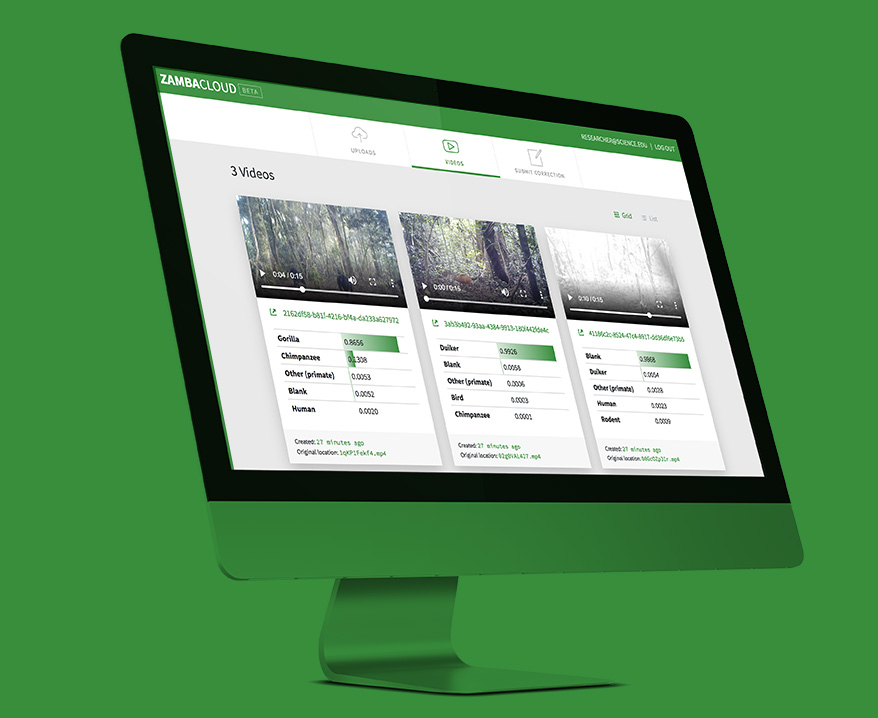
Once you have submitted data files, you can see their status on the Uploads page under the corresponding "Direct Uploads" or "FTP Uploads" tab. The status will say "Zamba processing succeeded" when the label spreadsheet is ready for download.
Since it can take a few days to process a large quantity of files, we'll send you an email from zamba@drivendata.org when the labels are ready. In the meantime, feel free to close the webpage and take a walk.
The link in the email will take you to your Uploads page, where there will be a button that says Download Labels. Click on this to download the csv file, which can be opened in Excel, Numbers, Google Sheets, or read by analytic software like R or Python.
You can re-download the labels at any point from your Uploads page when you are logged in. Once your media files are uploaded, you can also generate labels with other models by clicking Run different model.
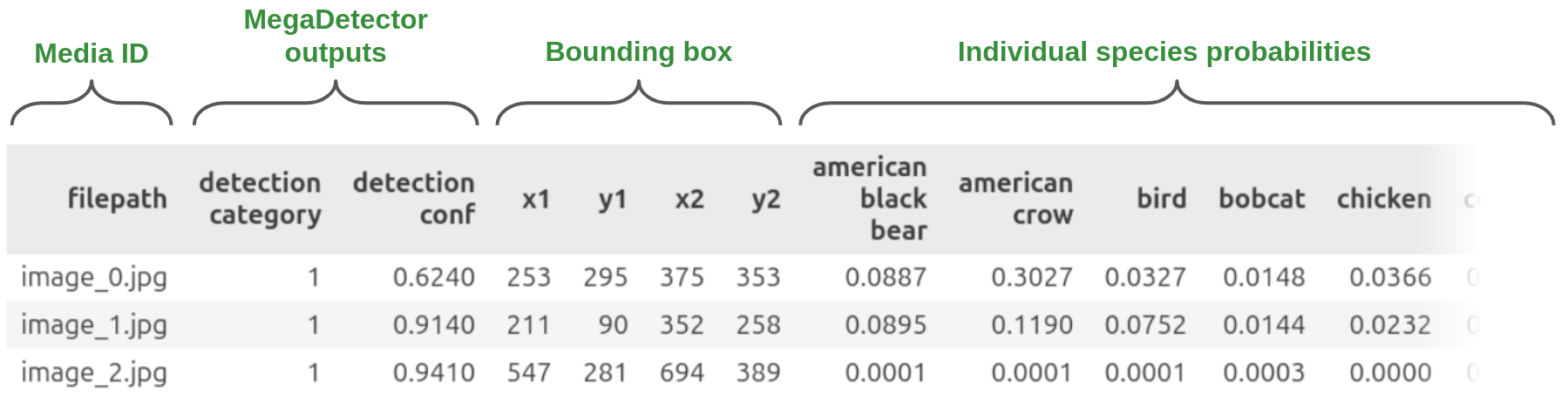
For each species label in the list above, Zamba Cloud uses an advanced computer vision model to estimate the probability that that label applies to the video or image. Probabilities range between 0 and 1. For each species label, 0 means the species is definitely not in the video, 0.5 means there's a 50% chance the species is in the footage, and 1 means the species is definitely in the video or image. For example, if the column for blank probability is 0.95 there is a 95% chance that the media has no animals in it.
The label spreadsheet format differs slightly for videos and images, so we will describe them separately below.
The labels spreadsheet has a row for each video. The columns are:
A labels spreadsheet could look like this:
| media_uuid | original_filename | top_1_label | top_1_probability | top_2_label | top_2_probability | ... | bird | blank | cattle | ... | corrected_label |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2056f94c | eleph.MP4 | elephant | 1.0000 | wild_dog_jackal | 0.0064 | 0.0021 | 0.0003 | 0.0046 | |||
| e267d8f3 | leopard.MP4 | leopard | 1.0000 | small_cat | 0.0203 | 0.0001 | 0.0000 | 0.0171 |
The labels spreadsheet has a row for each image. The columns are:
1 which represents "animal".You can filter all of your uploaded files on the Review Predictions page. Adjust the threshold slider based on what level of certainty you'd like to have that the videos/images contain the given animal.
For more fine-grained filtering, use the labels spreadsheet downloaded in the previous step. A few basic approaches:
top_1_label, top_2_label, top_3_label. The spreadsheet makes it easy to get a list of videos/images where you animal of interest is in the top 1, 2, or 3 most likely labels.lion column for rows with a value of 0.8 or greater.Either of these approaches can be used to filter out media files that contain no wildlife. Either filter for rows where none of the top 3 labels are blank, or apply a "less than" filter on the blank probability column.
Zamba Cloud relies on user-labeled data to improve its predictions. If you have videos or images where Zamba Cloud did not predict the right species, let us know!
The easiest way to submit corrections is using the downloaded labels spreadsheet. Right now this process is only supported for videos.
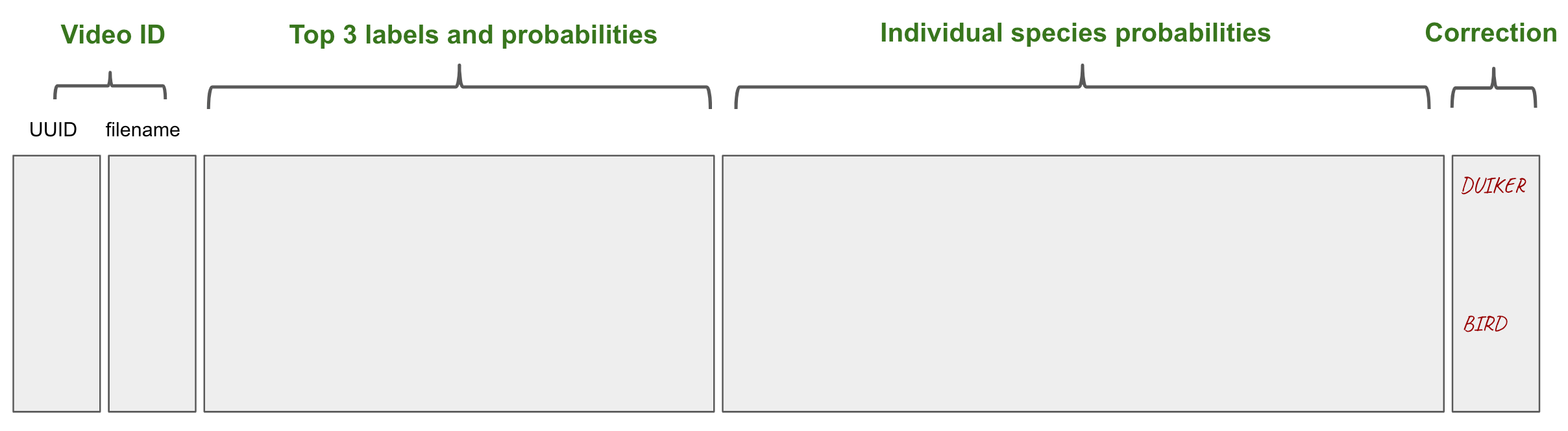
Fill in the corrected_label column - the last column in the spreadsheet.
chimpanzee_bonobo,
domestic_catCSV, which should be an
export option from your spreadsheet tool.media_uuid and corrected_label are ignored for the
corrections spreadsheet so you can leave these exactly how they were downloaded from Zamba Cloud.corrected_label per row (as shown above for video 123-456).top_1_label is correct, the corrected_label column
can be left blank or you can confirm the correct label by entering it in that column.Example spreadsheet of corrections:
| media_uuid | ... | ... | corrected_label | |
|---|---|---|---|---|
| 9ab-c65 | ... | ... | blank | |
| 89a-000 | ... | ... | ← video where label is already correct |
|
| 123-456 | ... | ... | duiker | ← video with multiple species |
| 123-456 | ... | ... | forest_buffalo |
Select the Review Predictions tab and then the Submit batch corrections button in the upper right corner. Then drag and drop or click Upload File to select the corrections spreadsheet you want to upload.
This section walks through how to train a model tailored to your own species or ecosystems. To train a model, you need to have a set of videos or images that are already labeled with the correct species. Your species can be either a subset of the ones that official models are already trained to predict, or completely new ones!
The more training data you have, the better the resulting model will be. We recommend having a minimum of 100 videos or images per species. Having an imbalanced dataset - for example, where most of the videos are blank - is okay as long as there are enough examples of each individual species.
Save a csv file with the correct labels for each training file on your local computer. The labels file should have columns for:
Example label file:
| filepath | label |
|---|---|
| blank.MP4 | blank |
| chimp.MP4 | chimpanzee_bonobo |
| eleph.MP4 | elephant |
| leopard.MP4 | leopard |
Use this option to upload labeled training videos from local files on your computer.
Direct uploads work best with a fast internet connection, as limited bandwidth can cause the browser to time out partway through the upload. If you have a slow internet connection, either check the "fast upload" box (which uses your computer's resources to reduce the size of the files before uploading), or consider an FTP upload instead.
FTP server uploading is only supported for video files at the moment. In order to use this option, your training videos have to already be uploaded to an FTP server. Many large organizations and universities run FTP servers, which can be used to host data for Zamba Cloud.
Upload your labeled media files.
Currently, Zamba Cloud is supported pro bono by DrivenData. Please reach out about funding opportunities for fiscal sustainability. More powerful paid versions for heavy users may be available in the future.
Because your labels can always be downloaded as a spreadsheet, you are not locked in to continuing to use this tool to access the labels that the algorithm predicted.
Depending on network conditions, you can expect processing to take about 12 hours for 1,000 videos. If you're experiencing issues, try limiting uploads to fewer than 2,500 videos at a time. Keep in mind that your job may take longer if it is in the queue behind another user's long running job.
Computer vision algorithms are only as good as the labeled data they're trained on. As a result, our official models can only predict the species that are included in the labeled training data we had available. Luckily, Zamba Cloud is a quick learner!
If you are able to gather labeled images or videos of your species of interest, you can pass those to Zamba Cloud and train a new model to identify your species. We recommend having at least 100 labeled images or videos of a species to retrain a model.
The retraining process starts with one of the official models, which has already learned from thousands of hours of camera trap footage. The model then continues training on the new data that you've provided.
For example, say that you want to identify ostriches specifically (who wouldn't? They're huge!). Our official model can identify "Large flightless bird," but that also includes things like emus. If you provide new labeled media files of "ostriches" specifically, the model will be able to combine its existing knowledge of how to identify all large flightless birds with the new information about how to distinguish ostriches from other species.
We're always looking for partners who can share their data to help us improve the accuracy on current species detection as well as expand to new species.
You can let us know where Zamba Cloud got things wrong by submitting corrected labels. If you have additional data that is already labeled, we'd love to hear from you at zamba@drivendata.org.
The algorithms behind Zamba Cloud are openly available for anyone to learn from and use. You can find the latest version of the project codebase on GitHub.
This project is structured as an open source command line tool and Python package, where you can run inference, train your own models, and even make your models available to the community.
You can cite the reference paper for the zamba python package:
Dorne, E., Qi, J., Bull, P., Stephens, C., Bessone, M., Debetencourt, B., Fruth, B., Morgan, D., Palmer, M. S., Sanz, C., Wendefeuer, J., Crockford, C., Deschner, T., Langergraber, K. E., Piel, A. K., Robbins, M., Sommer, V., Stewart, F. A., Wittig, R. M., . . . Arandjelovic, M. (2025). Zamba: Computer vision for wildlife conservation. Proceedings of the Python in Science Conferences, 85–111. https://doi.org/10.25080/crcw9835
This application has been developed and made available thanks to the generous support of WILDLABS, the Max Planck Institute for Evolutionary Anthropology, the Arcus Foundation, and the Patrick J. McGovern Foundation.
Built and maintained by DrivenData